Last time I’ve introduced you to the fundamentals of relational databases and SQL. Now it’s time for you to set up the working environment you need to follow along with this series. You will be using PostgreSQL as your RDBMS, so here’s what you need to get started.
Download and installation
PostgreSQL supports all major operating systems. You can go to the official download page, select your operating systems, and you will find all installation options. The installation process is straightforward, so I will try to cover it quickly.
For Windows and Mac, you can download the installer from the EDB website.
EDB no longer provides packages for GNU/Linux systems. Instead, they recommend that you use your distro’s package manager, which is much better after all.
The installers include different components, most importantly:
- PostgreSQL Server (obviously)
- pgAdmin, a graphical tool to manage your databases
- Package manager to download and install additional tools and drivers
Windows
After downloading the installer, launch it as any other executable. The process is just like any other standard installation, but some stuff is still noteworthy.
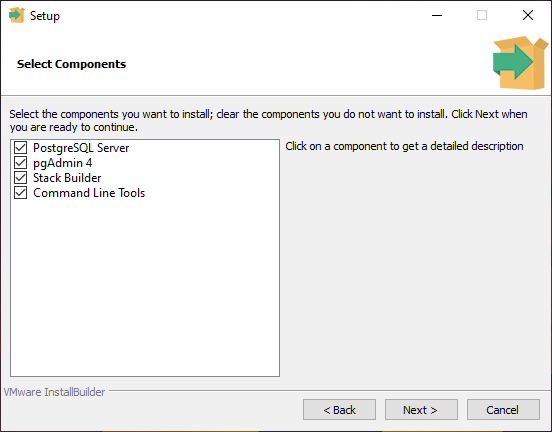
The “Select Components” dialog allows you to install components selectively. If you don’t have any good reason, you should leave it as it is and install them all, even if you think you won’t need them for now.
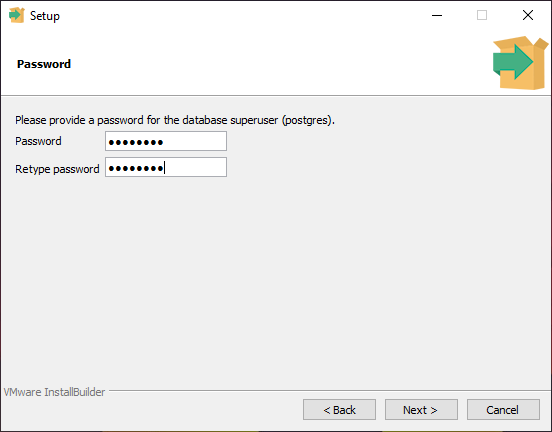
By default, PostgreSQL creates a superuser named postgres (think of it as the admin account of the database server). During installation, you will need to provide a password for the superuser. Later on, you can create other users and assign them permissions. We will get to this later on, but for now, you need a superuser account to start using the RDBMS.
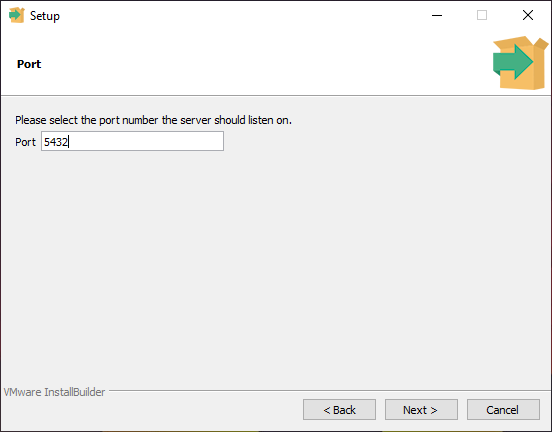
To run the development server (we will explain this in a minute) on your machine or localhost, you need to assign it a port to listen to it. The default port is 5432, and you shouldn’t change it unless you have a good reason to do so. For example, this port may already be taken by another PostgreSQL instance on your computer.
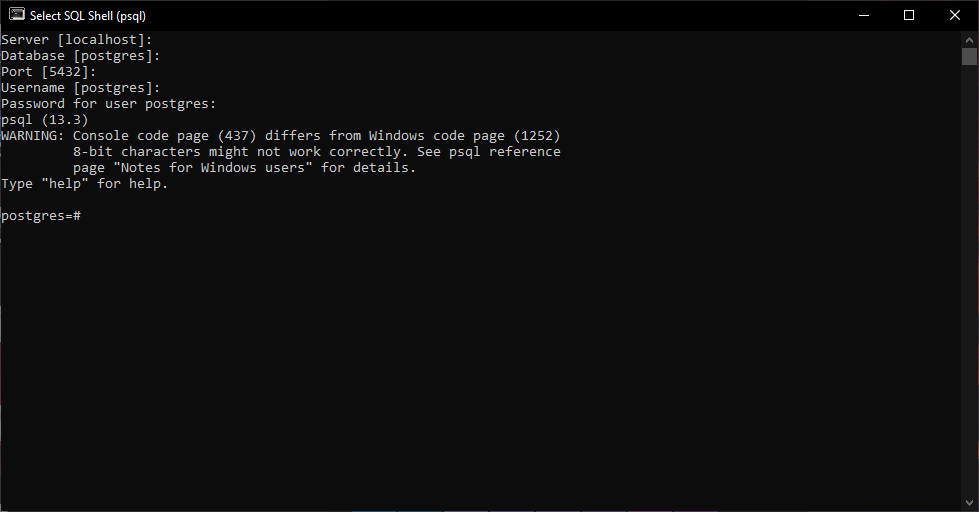
After the installation is complete, you can launch the SQL Shell that comes with Postgres.
Step by step, you’ll select the server, which database to use, port, username, and you need to provide the password for that user.
Use the details you’ve entered in the previous steps.
If you’re using Windows, then congrats! Your setup is complete, and you are ready to start writing SQL.
If your operating system is different, here are the options.
macOS
For macOS, you have different options. You can download the installer from the EDB website and run it.
Also, you can Postgres.app, which is a simple, native macOS app. You can execute it to have an up-and-running PostgreSQL server ready to use. You can also terminate the server by simply closing the app.
Alternatively, you can also use Homebrew, a package manager for macOS.
GNU/Linux
You can find PostgreSQL in repositories of most Linux distributions. You can install it with a single click from your graphical package manager of choice. You can also run a simple command to install the needed packages. You may want to refer to your distribution’s documentation for further details.
Ubuntu
sudo apt-get install postgresql
Ubuntu PostgreSQL configuration guide
Fedora
sudo yum install postgresql-server postgresql-contrib
Fedora PostgreSQL configuration guide
openSUSE
sudo zypper install postgresql postgresql-server postgresql-contrib
openSUSE PostgreSQL configuration guide
Arch
sudo pacman -S postgresql
Arch PostgreSQL configuration guide
Starting PostgreSQL Shell
Open the terminal and type:
psql -U postgres
psql is Postgres shell, -U argument is used to specify the user. Since you didn’t create any other users yet, you will log in as the superuser postgres. After that, you will be prompted to enter the superuser password you chose during installation.
Once the password is set, you’re ready to go.
If the PostgreSQL server didn’t start by default for some reason, you can manually start it using sudo systemctl start postgres
Understanding client-server model
I already mentioned PostgreSQL Server as being the important component in your installation. But what is a server in this context, and why do we need it?
For that, you need to understand the client-server model.
Almost all RDBMS (PostgreSQL, MySQL, and others) follow it. In this model, the database resides on the server, and the client sends requests to the server which handles them. The client here refers to our app.
These requests are mostly SELECT, INSERT, UPDATE and DELETE operations.
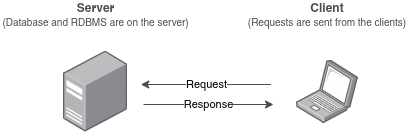
You need to have a local server to develop and test your apps locally instead of using a remote server for development purposes. This local server is the same as the remote, but it runs on your computer.
From the client’s point of view, a remote or a local server are identical. After developing and testing, you can make your product communicate with a remote server instead of the local one by simply changing a couple of parameters.
Some databases don’t use this model, for example, SQLite, which stores everything in a simple file on the drive. This works well for smaller applications, but you will need a client-server architecture for most real-world applications.
PostgreSQL meta-commands
Now that you have set up everything and are ready to start working with databases, there are few commands called meta-commands. These aren’t SQL commands, but they are specific to PostgreSQL. In other database management systems, you can use similar commands that are specific to that system.
All meta-commands are preceded with a backslash \ followed by the actual command. You’ll learn some of them right now.
List all databases
To get a list of all databases on your server, you can use the command \l. Typing this meta-command in the Postgres shell will output:
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-------------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
Which is a list of databases you have so far and their information such as the owner of the database, encoding, and access privileges. At this point, you didn’t create anything! these databases are created by default when you install Postgres. postgres is basically just an empty database. template0 and template1 are special databases that serve as a template when you create new ones later on. You shouldn’t worry about them right now, but you can check the official documentation if you want to read further about what they actually do.
Connect to a database
Some SQL commands require you to be logged into a database to work (such as creating a new table). You can choose which database to log into when you launch the SQL Shell.
When you are already inside the shell, you can use the \c command (or \connect) followed by the database name. If you had another database called hello_world, you could type:
`\c hello_world
The full command line looks like this:
postgres=# \c hello_world
You are now connected to database "hello_world" as user "postgres".
hello_world=#
You should notice that the shell prompt has changed from postgres to hello_world, indicating that you are now connected and operating in the hello_world database.
List all tables in a database
As with listing existing databases, you can also get a list of the tables inside a specific database using \dt command. Notice that you need to be logged into that database before executing this command.
Suppose you are already inside hello_world, which has a table called my_table. Typing \dt will output the following:
List of relations
Schema | Name | Type | Owner
--------+----------+-------+----------
public | my_table | table | postgres
You can see the name of the table and some other information, such as the schema (we will discuss schemas in more advanced tutorials) and the owner. The owner is the user who has created the table and owns it.
If you create other users and use them to create tables, you will see these users in the owner column instead.
List users and roles
As you know already, a superuser with the name postgres is created upon installing Postgres. If you create other users later and want to list them with their permissions, you can use the \dg command. This command outputs:
List of roles
Role name | Attributes | Member of
------------+------------------------------------------------------------+-----------
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
You notice that they are called roles, not users. In Postgres, users and roles are almost the same. Roles have attributes that define their permissions, like creating databases or even creating other new roles.
Any role with the LOGIN attribute can be considered as a user.
Here you see just one user, the default superuser. In the real world, you don’t want to be using the superuser all the time. Instead, you want to have other roles with fewer privileges. This will ensure that you (or other people in your system) don’t do unwanted things by mistake, such as deleting a database and spending a miserable weekend restoring it from the backup.
Your first SQL statement
Finally, you have everything set up. You know some basic PostgreSQL-specific commands. Now you are ready to start exploring SQL itself.
I will show you some basic examples to get the hang of it and get a feeling of SQL. But we will dive into it in more detail in the next article.
Creating a new database
The first thing you need to learn when learning databases is actually to create a database. This can be done using CREATE DATABASE command followed by the name you want for your database:
CREATE DATABASE store;
SQL commands and keywords are usually written in uppercase. This is not really a requirement, and usually, they are case-insensitive. But uppercase is generally preferred when writing SQL statements. It is a good practice because it can help you visually distinguish SQL keywords from other parts of the statement, such as tables and column names.
SQL statements should end with a semicolon ; . Although some database systems don’t require the semicolon, PostgreSQL requires it. It is a part of SQL standards, and you should write it. Postgres meta-commands don’t require a semicolon.
Creating tables
After you created a new database, you are ready to create tables in it. First, you need to connect to the new database using \c command followed by the name of the database:
\c store
Now that you are connected to the database (notice that the SQL shell prompt now includes the name of the active database), you are ready to create your first table. A table is created using CREATE TABLE command, followed by a list of the table columns and their datatypes inside parentheses:
CREATE TABLE products (
id INT,
name TEXT,
quantity INT
)
This will create a table called products which contains 3 columns:
idof typeINTor integer.nameof typeTEXTquantityalso of typeINT
Now that you have created your first table, you are ready to insert your first row of data into it.
Inserting data into tables
To insert rows of data into the table you have created, you can use the INSERT INTO command as follows:
INSERT INTO products (id, name, quantity) VALUES (1, 'first product', 20);
To break this command down:
INSERT INTOcommand means you are about to insert new dataproductsis the name of the table in your database where you want to insert the data(id, name, quantity)is a comma-separated list of the columns in our table. You don’t need to specify all the columns (otherwise, what’s the point of it?). In some cases, you want to insert data in some columns selectively. The other columns will be filled automatically with their default values.VALUES(1, 'first product', 20)are the actual data that will be inserted into the table.1is theid,first productis thename, and20is thequantity.
Selecting data
Now that your table contains data (just one row of data, sadly!), you can use SQL to query what’s in our table. Selecting data is done using the SELECT command, and it goes like this:
SELECT id, name, quantity FROM products;
We use the SELECT command followed by a list of the columns we want to retrieve. Then we use FROM to choose which table to get the data from. This time it’s the products table. You will get the following output in the shell:
id | name | quantity
---+---------------+----------
1 | first product | 50
Since you are selecting all the columns, you can use the following equivalent syntax instead:
SELECT * FROM products;
The asterisk means: select all the columns.
You must pay attention to how the SELECT command selects columns and rows. Columns are specified as a list and separated by commas. Then the command proceeds to select the requested rows. If no conditions are specified (like in this case), it will select all rows in the table. We will see later how to use conditions with the command to make powerful queries.
Updating data
Imagine you launched your awesome store app and got your first order on one of the products. One of the first things to do is update the available quantity in your inventory, so you don’t run into trouble later on. To update data, you can use the UPDATE command as follows:
UPDATE products SET quantity=49 WHERE id=1;
Let’s break this down again. First, there is the UPDATE command itself, followed by the name of the table. Then we use SET to set new values for our columns. After SET, you write the names of the columns you want to update, followed by an equal sign and the new updated value. You can update multiple columns at once by separating them using commas:
UPDATE products SET name='new name', quantity=49 WHERE id=1;
But wait, what rows are being updated by this command? You should have guessed it by now. To specify which rows to update with the new values, we use WHERE followed by a condition. In this case, we match the rows using their id column and update the row with the id of 1.
Deleting data
Now consider the case when you stopped selling a certain product and wanted to remove it from your database altogether. To do so, you can use the DELETE command:
DELETE FROM products WHERE id=1;
Similarly to updating data, you use WHERE followed by a condition specifying which rows to delete.
Dropping tables
You can also delete (or drop) a whole table. You can perform this using DROP TABLE:
DROP TABLE products;
This will delete the whole table from the database.
Be very careful with the DELETE command! No one ever wishes to drop the wrong table from the database by mistake.
Dropping databases
Similarly, you can drop a whole database from the system:
DROP DATABASE store;
Okay, I will trust you on not dropping the wrong database altogether in a production system. Reread the command a few times and consult your spouse before executing it.
Conclusion
Congratulations, you’ve made it!
You got your PostgreSQL installation up and running. You learned basic SQL commands and did some cool stuff with them. These few straightforward commands are the ones you will be using most of the time interacting with databases, so you should go and do some practice and exploration on your own. The next time, we will dive deeper and discuss Databases, Roles, and Tables in PostgreSQL.